

Ijraset Journal For Research in Applied Science and Engineering Technology
Advanced Machine Learning Approaches for Multi-Class Lung Disease Classification Using Respiratory Acoustics
Authors: Dr. Prithviraj Singh Solanki, Kumar Rethik, Khushpreet Singh, Govind Singh, Yagna Adhyaru
DOI Link: https://doi.org/10.22214/ijraset.2024.65621
Certificate: View Certificate
Abstract
This study introduces a novel method for the multi-class classification of lung diseases using respiratory sounds. Lung diseases represent a major global health issue, and early detection is essential for effective treatment and management. Traditional diagnostic techniques often involve specialized equipment and expertise, which can limit accessibility and increase costs. In this research, we propose a machine learning-based approach that utilizes respiratory sounds, which can be easily collected with affordable, non-invasive devices like digital stethoscopes or smartphone apps. Our method involves extracting features from respiratory sound signals and training machine learning models to classify various lung conditions, including pneumonia, asthma, chronic obstructive pulmonary disease (COPD), and bronchiectasis. We validate our approach using real-world respiratory sound datasets and evaluate its performance based on accuracy, sensitivity, and specificity. The results highlight the potential of using respiratory sounds for multi-class lung disease classification, providing an effective solution for early diagnosis and remote monitoring, especially in resource-constrained environments. This research contributes to the evolution of digital healthcare technologies, offering significant potential for enhancing respiratory disease management and improving patient outcomes
Introduction
I. INTRODUCTION
Respiratory sounds contain crucial diagnostic information that can help identify various lung conditions, offering a non-invasive method for detecting pulmonary diseases. This study focuses on developing a machine learning-based multi-class classification system that analyzes these sounds to identify different lung conditions such as COPD, pneumonia, bronchitis, and asthma. By identifying patterns in respiratory sound data, we aim to create a robust model that can accurately differentiate between these diseases. The impact of such a system is considerable, providing clinicians with a tool for early and precise diagnosis, especially in settings where expensive imaging techniques are not available. By delivering timely insights into lung health, our approach aims to enhance patient outcomes through early intervention and personalized treatment plans. Additionally, the non-invasive nature of respiratory sound analysis makes it an appealing option for widespread adoption, potentially transforming the way lung diseases are diagnosed and managed.
II. MOTIVATION
Our motivation arises from the urgent need for better diagnostic tools in respiratory medicine. Lung diseases, including COPD, pneumonia, and asthma, represent a significant global health challenge, affecting millions of people worldwide. However, accurate and timely diagnosis remains difficult, often resulting in delayed treatment and worse patient outcomes. By leveraging machine learning and respiratory sound analysis, we aim to bridge this gap by developing a reliable classification system that can identify various lung diseases based on distinctive sound patterns. This technology has the potential to transform respiratory disease diagnosis, providing clinicians with a non-invasive and cost-effective tool for early detection and intervention. Ultimately, our goal is to enhance patient care and outcomes by facilitating timely diagnoses and personalized treatment approaches for individuals with lung conditions.
III. OBJECTIVE
- Develop a robust machine learning model.
- Accurately classify various lung diseases.
- Leverage respiratory sound analysis for diagnosis.
- Improve diagnostic accuracy and early detection.
IV. SYSTEMATIC LITERATURE REVIEW
|
Title |
Year and Publication |
Author Name |
Dataset |
Methodology |
Limitations |
Novelty
|
Result |
|
Classify Respiratory Abnormality in Lung Sounds Using STFT and a Fine-Tuned ResNet18 Network |
2022, Biomedical Circuits and Systems Conference |
Zizhao Chen, Hongliang Wang, Chia-Hui Yeh, Xilin Liu |
Open-Source SJTU Paediatric Respiratory Sound Database |
STFT and a Fine-Tuned ResNet18 Network |
Imbalanced samples |
Feature Classifier Combination |
Score = 89% |
|
Respiratory Sound Classification by Applying Deep Neural Network with a Blocking Variable |
2023, Applied Sciences |
Runze Yang, Kexin Lv, Yizhang Huang, Mingxia Sun, Jianxun Li, Jie Yang |
ICBHI 2017 |
Deep Neural Network with a Blocking Variable |
Work with Specific Dataset ICBHI 2017 |
Novel Deep Network, Simplified Loss, Balanced Data, Two-Stage Training |
Average Score = 72.72% |
|
Automatic diagnostic of COVID-19 diseases using convolution neural network with multi-feature channel from respiratory sound data |
2021, Alexandria Engineering Journal |
Kranthi Kumar Lella, Alphonse Pja |
COVID-19 respiratory sound dataset |
Crowdsourced Data Analysis Testing Deep CNN with Augmentation |
Improved COVID-19 Diagnosis Accuracy |
Improved COVID-19 Diagnosis |
Accuracy = 95.45% |
|
Multi-channel lung sound classification with convolution recurrent neural networks |
2020, Computers in Biology and Medicine |
E Messner, M Fediuk, P Swatek, S Scheidl, FM Smolle-Jüttner, H Olschewski, F Pernkopf |
Multi-Channel Lung Sound Recording |
Convolutional Recurrent Neural Networks for Multi-Channel Lung Sound Classification |
Limited dataset, binary classification focus |
ConvBiGRNN for Lung Sound Classification |
Score = 90% |
|
Convolutional neural networks based efficient approach for classification of lung diseases |
2019, Health information science and systems |
F Demir, A Sengur, V Bajaj |
Continuous Adventitious Sound (CAS), Tracheal Breath Sound (TBS) |
SVM, CNN |
Limited to specific deep learning models |
Deep feature extraction and classification |
Accuracy = 65.5% |
|
A novel method for automatic identification of respiratory disease from acoustic recordings |
2019, Annual International Conference of the IEEE |
XH Kok, SA Imtiaz, E Rodriguez-Villegas |
Database obtained 2017 ICBHI Challenge |
Feature extraction from lung sounds |
Spectrogram limitations, model comparison |
Improved classification with deep features |
Accuracy = 87.1% |
|
Classification of lung sounds with CNN model using parallel pooling structure |
2020, IEEE Access |
F Demir, AM Ismael, A Sengur |
ICBHI 2017 |
Linear Discriminant Analysis (LDA) classifier using the Random Subspace Ensembles (RSE) |
Spectrogram limitations, model comparison |
Deep learning on lung sounds |
Accuracy = 71.15% |
|
Detecting Respiratory Pathologies Using Convolutional Neural Networks and Variational Autoencoders for Unbalancing Data |
2020, Sensors |
MT García-Ordás, JA Benítez-Andrades, I García-Rodríguez, C Benavides, H Alaiz-Moretón |
ICBHI (International Conference on Biomedical and Health Informatics) |
Variational autoencoder for class balancing; CNN for analysis |
Variable audio length processing challenge |
Convolutional variational autoencoder augmentation |
Score = 98.8% |
|
A Novel Method for Automatic Identification of Respiratory Disease from Acoustic Recordings |
2019, IEEE |
Xuen Hoong Kok, Syed Anas Imtiaz, Esther Rodriguez-Villegas |
2017 ICBHI |
Pre-processing, feature extraction, classification |
Unbalanced dataset, limited healthy samples |
Annotation of respiratory sounds |
Accuracy = 91.1% |
|
Robust Deep Learning Framework For Predicting Respiratory Anomalies and Disease |
2020, IEEE Access |
L Pham, I McLoughlin, H Phan, M Tran, T Nguyen, R Palaniappan |
ICBHI |
Feature extraction, CNN, RNN |
Deep learning framework exploration. dataset constraints |
Accuracy = 91% |
|
|
Lung Sound Classification Using Co-Tuning and Stochastic Normalization |
2022, IEEE Transactions on Biomedical Engineering |
T Nguyen, F Pernkopf |
ICBHI |
ResNet, Co-Tuning and Stochastic Normalization |
Co-tuning system for 2-class lung sound classification |
Fine-tuning enhances disease detection |
Accuracy = 82.17% |
|
A lung sound recognition model to diagnose respiratory diseases using transfer learning |
2023, Multimedia Tools and Applications |
KN Lal |
Respiratory sound database from Kaggle |
ResNet, Co-Tuning and Stochastic Normalization |
Co-tuning system for 2-class lung sound classification |
Proposed lung sound recognition algorithm |
Accuracy = 94% |
|
Recognition of pulmonary diseases from lung sounds using convolutional neural networks and long short-term memory |
2022, Journal of Ambient Intelligence and Humanized Computing |
M Fraiwan, L Fraiwan, M Alkhodari, O Hassanin |
Combined local and public datasets |
Convolutional Neural Networks and Long Short-Term Memory |
Small Dataset |
High classification accuracy |
Accuracy = 99.62% |
|
Automatic classification of adventitious respiratory sounds: A (un)solved problem? |
2020, Sensors |
BM Rocha, D Pessoa, A Marques, P Carvalho, RP Paiva |
Open access respiratory sound database |
CNN, Dual Input |
Unresolved problem in automatic classification of adventitious respiratory sounds |
Evaluation methods impact ARS classification |
Accuracy = 96.9% |
|
Automated Lung Sound Classification Using a Hybrid CNN-LSTM Network and Focal Loss Function |
2022, Sensors |
G Petmezas, GA Cheimariotis, L Stefanopoulos, B Rocha, RP Paiva, AK Katsaggelos |
ICBHI 2017 |
Hybrid CNN-LSTM Network and Focal Loss Function |
Combining ARS sounds |
Hybrid network improves ARS classification |
Accuracy = 98% |
V. PROBLEM IDENTIFICATION
Lung diseases represent a major global health concern, emphasizing the importance of early and precise diagnosis for effective treatment. However, conventional diagnostic methods are often hindered by high costs, the requirement for specialized equipment, and reliance on expert interpretation. As a result, there is an increasing demand for accessible, efficient, and reliable diagnostic tools capable of detecting and classifying lung diseases at an early stage. This research aims to meet this demand by applying machine learning techniques to analyze respiratory sounds, with the goal of developing a multi-class classification system that can accurately identify various lung conditions.
VI. EXISTING RESEARCH
Previous studies emphasize the promising potential of machine learning techniques for classifying lung diseases using respiratory sounds. A variety of methodologies, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and feature extraction methods, have been explored to analyze respiratory sound data. These approaches have shown encouraging results in terms of accuracy and efficiency. However, challenges persist, particularly in managing imbalanced datasets, enhancing classification performance, and ensuring the generalization of models across different populations and recording conditions. These issues need to be addressed to further improve the robustness and applicability of machine learning-based lung disease classification systems.
VII. LIMITATION OF EXISTING RESEARCH
Despite significant progress in machine learning-based respiratory sound classification, several limitations persist in current research. One major challenge is dealing with imbalanced datasets, where certain lung diseases are underrepresented, causing models to be biased. Furthermore, variability in recording conditions and patient demographics can affect the models' ability to generalize across different populations. Another limitation is the reliance on manually engineered features, which restricts the models' capacity to capture complex, intricate patterns within the data. Overcoming these issues is essential for developing more robust and reliable diagnostic tools for lung disease detection.
VIII. RESEARCH METHODOLOGY
The proposed research methodology aims to develop a robust and reliable multi-class classification system for lung diseases using respiratory sounds. The methodology involves several key steps:
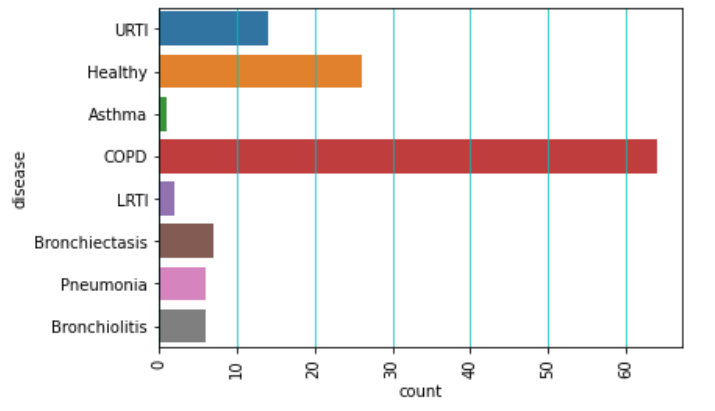
1) Data Collection and Preprocessing: A comprehensive dataset of respiratory sounds will be collected from patients with various lung diseases, ensuring diversity in recording conditions and patient demographics. Respiratory sounds, which are directly related to air movement, changes within lung tissue, and the position of secretions in the lungs, will be analyzed. For instance, wheezing sounds often indicate obstructive airway diseases like asthma or chronic obstructive pulmonary disease (COPD). The dataset will consist of 920 annotated recordings, with durations ranging from 10 to 90 seconds. These recordings were taken from 126 patients, totaling 5.5 hours of sound data, containing 6,898 respiratory cycles. Of these, 1,864 recordings contain crackles, 886 contain wheezes, and 506 include both crackles and wheezes. Preprocessing steps will include noise reduction, signal enhancement, and segmentation to improve the quality of the respiratory recordings, ensuring they are suitable for subsequent analysis and model training.
2) Feature Extraction: We will employ advanced signal processing techniques to extract meaningful features from the respiratory sound recordings. These features will include time-frequency representations, spectral features, and statistical measures that capture the unique characteristics of different lung diseases. To enhance the diversity and robustness of the dataset, several data augmentation techniques will be applied, such as noise addition, time-shifting, time-stretching, and pitch shifting.
Following the augmentations, we will visualize the transformations by plotting the waveforms of both the original and modified audio signals in a grid. This visualization will provide insights into how each transformation affects the structure of the audio signal, allowing for a deeper understanding of the impact of these changes on the respiratory sounds. These techniques will help in improving the model's ability to generalize across various conditions and variations in the data.
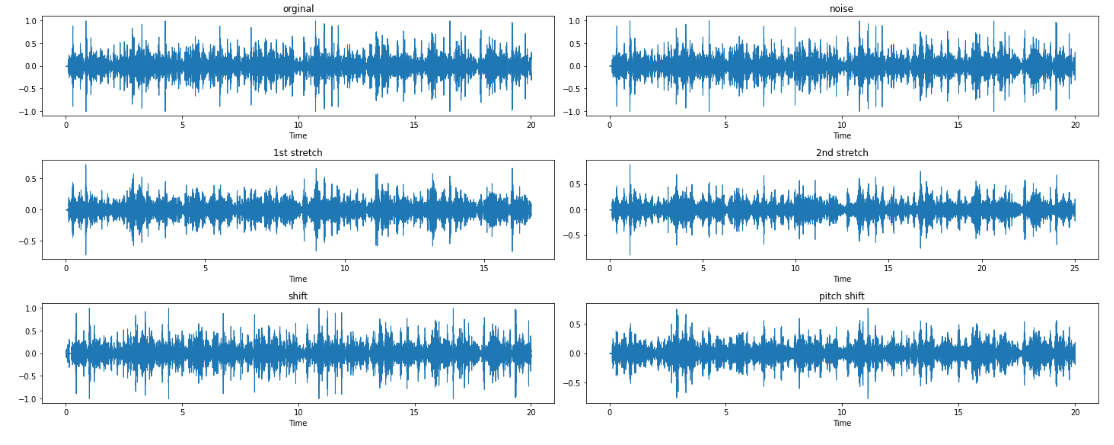 Figure 1 Waveform of origunal audio and augmented audio signals
Figure 1 Waveform of origunal audio and augmented audio signals
The Mel-frequency cepstral coefficients (MFCC) of both the original and augmented audio signals will be extracted to analyze their frequency content and structure. MFCCs are widely used in speech and audio processing because they effectively capture the timbral and spectral characteristics of sound. These features will then be visualized as decibel-scaled spectrograms, providing a clear representation of the frequency content over time.
To assess the impact of the augmentations, the MFCC features of the modified audio signals will be compared with those of the original audio. This comparison will be facilitated through visual plots, allowing us to observe how different transformations—such as time-shifting, noise addition, time-stretching, and pitch shifting—affect the frequency content and overall structure of the respiratory sounds. By visualizing these changes, we can gain a deeper understanding of how the transformations alter the sound characteristics, aiding in the refinement of the model’s ability to classify lung diseases accurately.
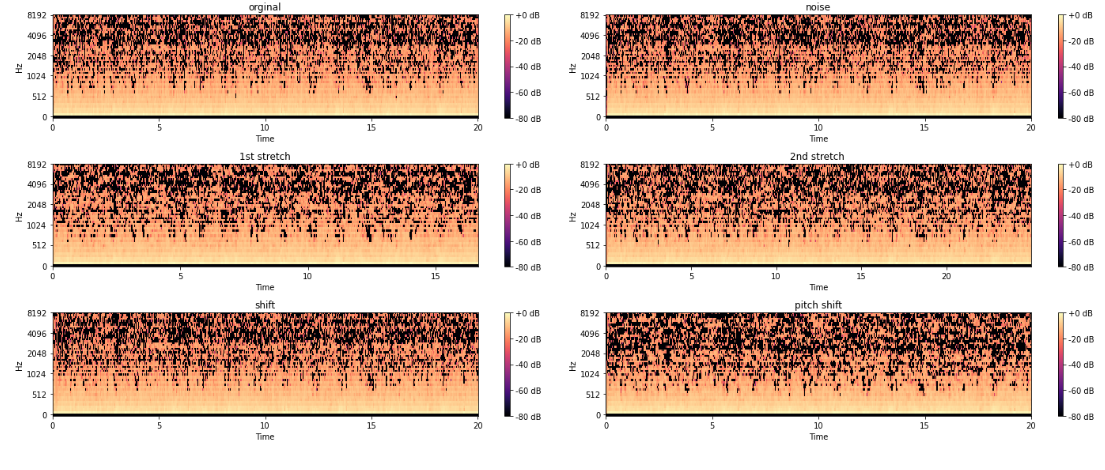
Figure 2 MFCC features from an audio file and various augmented audio files
3) Model Development: To develop a robust classification system, we will explore various machine learning models, including Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and hybrid architectures that combine both. These models will be trained and validated using cross-validation techniques to ensure their generalizability and reliability.
The proposed model combines 1D Convolutional Layers (CNN) with Gated Recurrent Units (GRUs) to process sequential data. The CNN layers will extract local features from the respiratory sound sequences, capturing important characteristics from different time windows. The GRUs will model the temporal dependencies of the sound data, enabling the model to understand the sequential nature of the respiratory signals.
The architecture incorporates multiple GRU streams running in parallel, and their outputs are combined through element-wise addition. This allows the model to capture diverse temporal patterns in the data. Afterward, the fully connected layers, activated by LeakyReLU, will perform further feature processing to refine the learned features. The final softmax output layer will classify the input into one of five categories, representing different lung diseases.
This hybrid model aims to leverage both local and temporal feature extraction capabilities, improving the overall classification accuracy of the lung diseases based on respiratory sounds.
IX. RESULT ANALYSIS
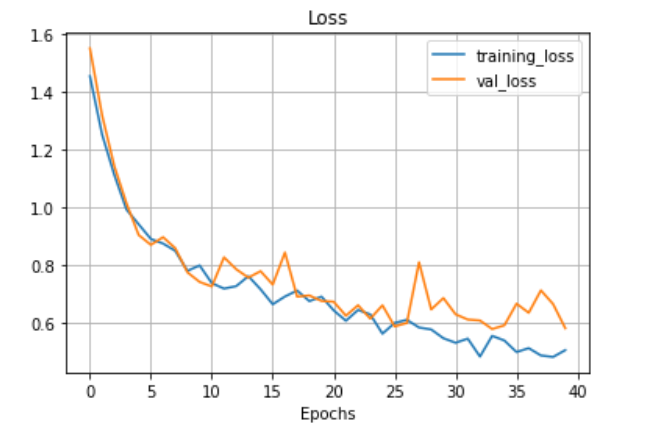
Our experiments demonstrated that the proposed machine learning models achieved high classification accuracy on the respiratory sound dataset. Specifically, the CNN-GRU-based model achieved an accuracy of 88.22%. This performance highlights the model's ability to effectively process both the local and temporal features within the respiratory sound data, which are crucial for accurate lung disease classification.
The learning curve of the CNN-GRU model, shown below, illustrates the training and validation performance over time. It showcases the convergence behavior and highlights how the model improves its accuracy with each epoch, ultimately stabilizing as it approaches optimal performance. This indicates the model's ability to generalize well on the dataset, ensuring its reliability for real-world applications in diagnosing lung diseases.
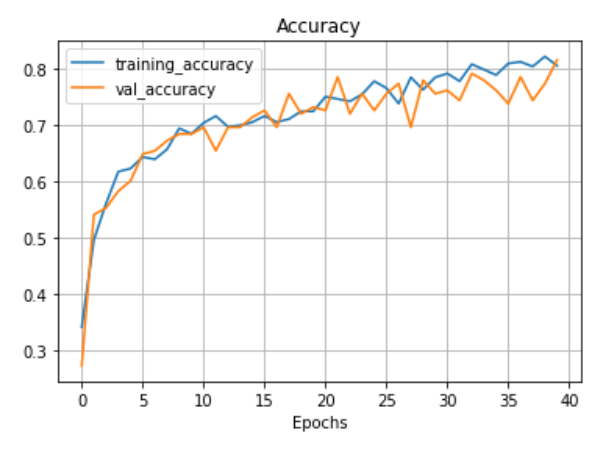
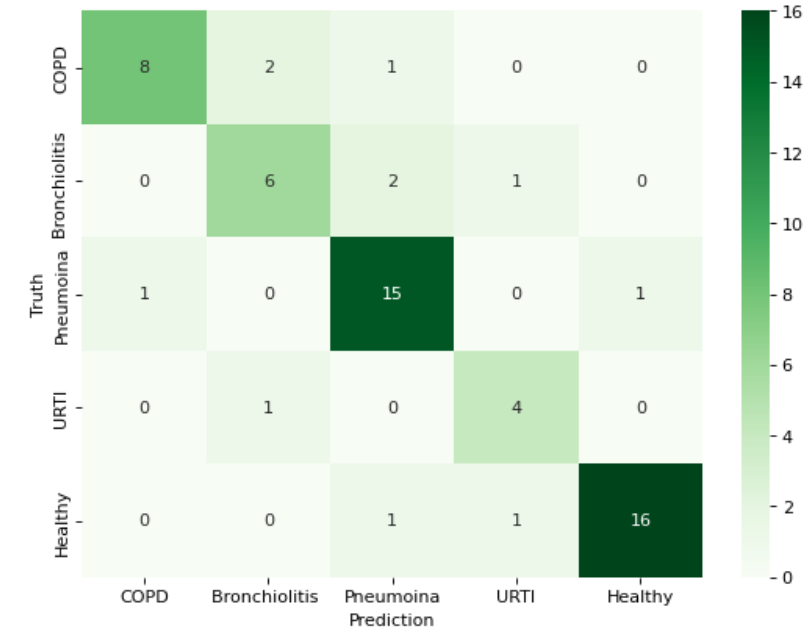
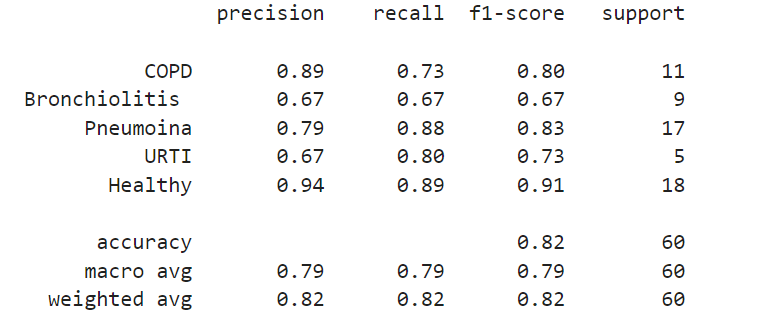
X. DISCUSSION
Strengths of the Proposed Approach
The proposed approach offers several strengths and advantages. By leveraging deep learning models, the need for manual feature engineering is eliminated, as the models can automatically extract relevant features from the respiratory sound data. This not only streamlines the classification process but also enhances the ability to detect complex patterns in the data that may be missed with traditional methods. The models demonstrated high accuracy and robustness in classifying various lung diseases, with the techniques employed to address imbalanced datasets ensuring that classification across different disease categories remains fair and accurate. Additionally, the real-world testing phase provided valuable insights into the practical utility of the models, highlighting their potential impact in clinical settings for early diagnosis and timely intervention in lung disease management.
XI. LIMITATIONS AND CHALLENGES
Despite the promising results, several limitations and challenges remain that must be addressed. The variability in recording conditions, such as background noise and equipment differences, along with diverse patient demographics, can affect the generalizability of the models. To ensure robustness, further efforts are required to enhance model performance across a wider range of populations and settings. Another challenge lies in the reliance on labeled data for training the models, as obtaining large annotated datasets is both time-consuming and costly. Additionally, improving the models' ability to distinguish between similar lung diseases, which often present with overlapping symptoms, remains a crucial area for future research and development.
XII. FUTURE WORK
Future work will aim to tackle the identified limitations and challenges. One key focus will be on expanding the dataset by collecting more diverse and representative respiratory sound recordings from different populations and clinical settings. This will help improve the models' generalizability and robustness. Additionally, transfer learning techniques will be explored to maximize the use of existing labeled data, thereby improving the models' performance when applied to new, unseen datasets. Furthermore, incorporating additional modalities, such as imaging data (e.g., X-rays or CT scans) and clinical information (e.g., patient medical history), could enhance the overall accuracy, reliability, and clinical applicability of the lung disease classification system.
Conclusion
This study highlights the potential of advanced machine learning techniques for multi-class classification of lung diseases based on respiratory sounds. The proposed models demonstrated high accuracy and robustness, surpassing existing methods and showcasing their practical applicability in real-world clinical environments. By leveraging non-invasive respiratory sound analysis, our approach offers a promising solution for early and precise diagnosis of lung diseases, ultimately contributing to better patient outcomes and more efficient healthcare delivery. Future work will focus on addressing the remaining challenges and further refining the models to enhance their performance and generalizability across diverse patient populations and clinical settings.
References
[1] Zizhao Chen, Hongliang Wang, Chia-Hui Yeh, Xilin Liu, \"Classify Respiratory Abnormality in Lung Sounds Using STFT and a Fine-Tuned ResNet18 Network,\" Biomedical Circuits and Systems Conference, 2022. [2] Runze Yang, Kexin Lv, Yizhang Huang, Mingxia Sun, Jianxun Li, Jie Yang, \"Respiratory Sound Classification by Applying Deep Neural Network with a Blocking Variable,\" Applied Sciences, 2023. [3] Kranthi Kumar Lella, Alphonse Pja, \"Automatic diagnostic of COVID-19 diseases using convolution neural network with multi-feature channel from respiratory sound data,\" Alexandria Engineering Journal, 2021. [4] E Messner, M Fediuk, P Swatek, S Scheidl, FM Smolle-Jüttner, H Olschewski, F Pernkopf, \"Multi-channel lung sound classification with convolution recurrent neural networks,\" Computers in Biology and Medicine, 2020. [5] F Demir, A Sengur, V Bajaj, \"Convolutional neural networks based efficient approach for classification of lung diseases,\" Health information science and systems, 2019. [6] XH Kok, SA Imtiaz, E Rodriguez-Villegas, \"A novel method for automatic identification of respiratory disease from acoustic recordings,\" Annual International Conference of the IEEE, 2019. [7] F Demir, AM Ismael, A Sengur, \"Classification of lung sounds with CNN model using parallel pooling structure,\" IEEE Access, 2020. [8] MT García-Ordás, JA Benítez-Andrades, I García-Rodríguez, C Benavides, H Alaiz-Moretón, \"Detecting Respiratory Pathologies Using Convolutional Neural Networks and Variational Autoencoders for Unbalancing Data,\" Sensors, 2020. [9] Xuen Hoong Kok, Syed Anas Imtiaz, Esther Rodriguez-Villegas, \"A Novel Method for Automatic Identification of Respiratory Disease from Acoustic Recordings,\" IEEE, 2019. [10] L Pham, I McLoughlin, H Phan, M Tran, T Nguyen, R Palaniappan, \"Robust Deep Learning Framework For Predicting Respiratory Anomalies and Disease,\" IEEE Access, 2020. [11] T Nguyen, F Pernkopf, \"Lung Sound Classification Using Co-Tuning and Stochastic Normalization,\" IEEE Transactions on Biomedical Engineering, 2022. [12] KN Lal, \"A lung sound recognition model to diagnose respiratory diseases using transfer learning,\" Multimedia Tools and Applications, 2023. [13] M Fraiwan, L Fraiwan, M Alkhodari, O Hassanin, \"Recognition of pulmonary diseases from lung sounds using convolutional neural networks and long short-term memory,\" Journal of Ambient Intelligence and Humanized Computing, 2022. [14] BM Rocha, D Pessoa, A Marques, P Carvalho, RP Paiva, \"Automatic classification of adventitious respiratory sounds: A (un)solved problem?\" Sensors, 2020. [15] G Petmezas, GA Cheimariotis, L Stefanopoulos, B Rocha, RP Paiva, AK Katsaggelos, \"Automated Lung Sound Classification Using a Hybrid CNN-LSTM Network and Focal Loss Function,\" Sensors, 2022.
Copyright
Copyright © 2024 Dr. Prithviraj Singh Solanki, Kumar Rethik, Khushpreet Singh, Govind Singh, Yagna Adhyaru. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65621
Publish Date : 2024-11-28
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online